TL;DR
Legacy system on AWS — $734 per month
Combination of GCP and Digital Ocean — $200 per month
Background
In retrospect, even the AWS bill can be brought down if we properly set things up in AWS. The downside is that AWS is an overkill for a small team of 5–10 people where developers are expected to wear multiple hats and there isn’t a requirement for a specialist. Most often, it is very hard to find options to tweak or debug when something is wrong. Since we’re redesigning the architecture from the ground up, we choose the vendors and the services which were aligned with the interests of a smaller team to manage the infra without the additional cost of formal training in AWS.
Now a little about the business, these guys are a hardware company who do analytics and had steady sales for 5 years and had perfected their niche and were growing.
They had to set up their whole infrastructure in AWS and it was kind of rusty. In 2015, AWS was a popular place for small businesses to host their servers due to the ecosystem, expertise, and community surrounding AWS. For a small business, it would be quite counter-intuitive to host your server anywhere else because AWS had everything.
A lot of legacy systems are in AWS even though there are better alternatives and tools when you compare ease-of-use, docs, services, and community. Companies starting up right now are choosing competitively on where to host their system from a range of options like GCP, Digital Ocean, AWS, Azure, IBM. Most of the deployment processes have been reduced to just a few clicks, that it’s totally worth exploring the bunch of services that would make maintenance, deployment, and monitoring easier now or consider upgrading your already existing system to the vendor which aligns with your business and team.
Also, that’s not the only thing that’s different from 2015. We now have a mature ecosystem of tools to host, deploy, and maintain our infrastructure. Terraform is a very popular Open-Source project where you can literally code your infrastructure and host it in the cloud of your choice. This also makes sure you don’t get vendor-locked because with Terraform you could move away from AWS and deploy it to the vendor of your choice with a couple of clicks. Also, in 2020, It’s hard to find a project which isn’t dockerized and this server wasn’t. A single developer can orchestrate this configuration easily in the weekend.
Why We Chose to Move Away From AWS
Don’t get me wrong, AWS is great! It was truly a pioneer in Cloud but then there are caveats to a giant like AWS. As someone who started working with and got acquainted with Cloud last year, I’ll give you a bunch of reasons why AWS sucks, but then we’d be moving away from the gist of the article, so you can just go and read this [extensive rant which dissects this topic really well.](https://medium.com/@nandovillalba/why-i-think-gcp-is-better-than-aws-ea78f9975bda)
When all you’re trying is to get your business up and running, most developers do not have the time nor the patience to go through all these obscure docs and tools when you could directly get stuff up and running when you’re trying to prove the validity of your business. The prime reason for moving away is that AWS is too cluttered and confusing for the team, no one knows where all the options are, and having a dedicated DevOps or a Cloud person to handle deployment is just overkill for the team. It was better to move to a vendor that a single Backend Engineer could get acquainted with within a day.
So the existing infrastructure, there is running a Django server configured with Gunicorn on 3 instances AWS Elastic Beanstalk. They use 2 CPU, 4 GB Ram Postgres RDS instance as their database and they have another database for staging and testing purposes and it works well for them. At their peak hours get about 20000 requests per hour. Since this product is active in the US, it’s configured in us-central1. I come into the scene to migrate this and remove the head-aches. 👉🏿😎👉🏿
I have previous experience with managing infrastructure in GCP, some Data Engineering and Backend here and there, and I’ve worked with Databases. I’m not permanently associated with this company, they brought me in as a contractor to reduce the Cloud bill and make their infra easier to manage. These are all anecdotal details I gathered from talking with the developers there and I didn’t get access to their AWS dashboard to inspect the whole thing close.
Analysis Of The Existing System
Let’s now get to the problems and get our hands dirty. The most crucial problem was in AWS, the server was running 3 instances of AWS Elastic Beanstalk. The system was not set up for auto-scaling, as far as I know. At peak hours, they get around 10k-20k requests per hour and the server handled that quite well.

These peaks were only during the weekends and day-time when usage is the highest and it eventually settles in during the night. So we’re running at the full capability of handling these 20k requests even when it is not required and racking up additional server costs. Definitely an avenue for improvement. Each of the 3 EC2 instances also has a Redis instance running in it for Caching and CRON jobs which were configured running in each of the three instances which could definitely be designed better.
There are two instances of Postgres 2 vCPU, 4 GB Ram RDS running as a production server and a staging server. We can look at the database costs across 3 different service providers for comparison too. There are 5 CRON Jobs that are pretty heavy and configured within Django to run daily, these generate Customer analytics CSVs and other tasks which run within the instance.
At the end of the day, the total server cost comes around $800. It’s not too much, but that’s not the point. The point is that things can be optimized and managing can be made easier. We could cut the server cost in half if we’re setting the thing up properly and make it a third if you want to go really really frugal.

Make the Server Auto-Scale Based on Demand
Why Cloud Run?
So the first problem to be solved is auto-scaling. The traffic of 20,000 per hour means that at most, our server should be configured to handle 10–20 concurrent requests per second during the peak hours and then scale-down to normal traffic when things are normal in the night.
There are a lot of ways to make the server auto-scale, the ideal way is to containerize it and deploy it on Kubernetes. But wait, isn’t Kubernetes pretty obscure, and doesn’t it add complexity to developer efforts? For small teams, yes. That’s where Cloud Run by Google Cloud comes in. In Google’s word, it is
Fully managed compute platform for deploying and scaling containerized applications quickly and securely.
Cloud Run is a managed compute platform that enables you to run stateless containers that are invocable via web requests or Pub/Sub events. Cloud Run is serverless: it abstracts away all infrastructure management, so you can focus on what matters most — building great applications. It is built from Knative, letting you choose to run your containers either fully managed with Cloud Run, in your Google Kubernetes Engine cluster, or in workloads on-premises with Cloud Run for Anthos.
What is Knative?
Knative (pronounced kay-nay-tiv) is an open-source community project which adds components for deploying, running, and managing serverless, cloud-native applications to Kubernetes. The serverless cloud computing model can lead to increased developer productivity and reduced operational costs.
Okay, we do not need to get into the technicalities of Kubernetes, but how would this service benefit the business? For one, Knative is an Open Source project, so you won’t get vendor-locked in your future. Two, going serverless and using the managed instance helps us to cut our server costs, scale and manage infra quite easily. Once the migrations and auto-deployment are set up, the ease monitoring, scaling, and logging becomes simplified. And Google built this product thinking of developers in mind.
And the official Cloud-Run product team is quite active on Twitter!
Additionally, deployment using Knative is not an option on AWS. For migrations, You’ll need to prepare your server to go through this migration and test it thoroughly to see if it’ll handle the peak traffic and tune the production settings. We’ll get right into the business and prepare our server for migration.
Dockerize
Depending on the server, it’d be different, but then Dockerizing the project is the easy part. The hard part is configuring the settings which the creators may or may not have forgotten about.
FROM python:3.7
WORKDIR /app
COPY requirements.txt /app
RUN pip install -r requirements.txt
COPY . /app
RUN mkdir log && touch log/debug.log
RUN chmod 777 /app/log/debug.log
EXPOSE 8000
CMD ["uwsgi", "--ini", "uwsgi/uwsgi.ini"]
In our case, we used uwsgi and I had to spend a good amount of time configuring Django settings to make things like collectstatic and staticfiles work proper, setting up Docker for testing locally and writing docs because there were none.
I do not want this article to deviate from the topic of migrating from AWS, so if it’s necessary, I’ll write another article on exactly how I prepared it for migration. In short, I did the following
-
Deliver Staticfiles from Google Cloud Storage CDN instead of AWS Buckets.
-
Migration and collectstatic while we push to our server.
-
Setting up Caching in Memorystore for testing performance, and then running the Cache in a VM for reducing cost.
-
Load-testing using Locust to see if it handles the load. We tested Cloud Run and mocked 20 concurrent requests per second for more than an hour using our APIs and it scaled quite well without dropping any requests.
-
Setting up monitoring and alerting to capture if something fishy happens.
In the end, these were the Cloud Run settings we went with.
Setting up the CRON Jobs
So onto the next step. We have CRON scripts configured within the Elasticbeam instances to multiple tasks from generating CSVs to calculating metrics. Some of them were light-weight, some were quite heavy. So you ask “wouldn’t this run 3 times within each of the three EC2 instances potentially wasting resources?”. Yes, it would. The scripts are written so that these multi-writes are accounted for, but still, it’s best to isolate this flow from the server and host it elsewhere.
So how do we do that? Cloud Scheduler, pub-sub, and a VM.
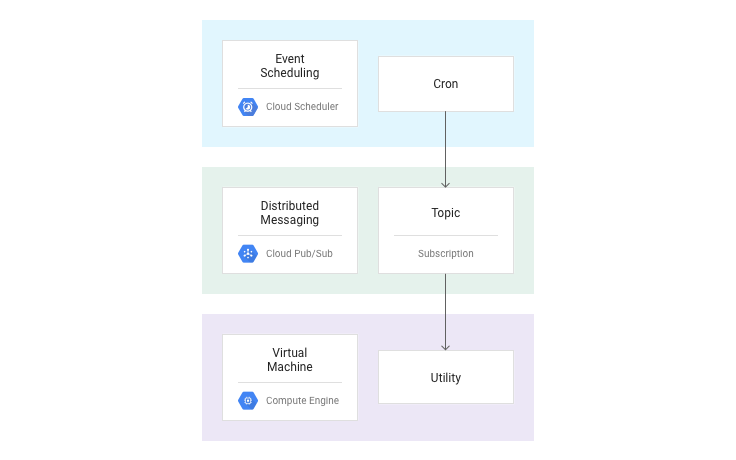
Cloud-Scheduler
It’s a CRON, but on the web. You can visually time tasks and run them.

Pub/Sub
Pub/Sub is a queue. It’s what delivers the message from our Cloud Scheduler to our VM where we’ll set up our scripts separate from our server which is serving traffic.
Droplet
We can use a micro VM instance from either GCP or Digital Ocean and it would only cost us about $15 — $30. We’ll set up a script to receive the pub-sub tasks and then execute our 5 different CRON jobs and the log everything into GCP Cloud Logger.
Cost Comparison
CRON VM: A 2GB, 1vCPU instance for running our CRON on Digital Ocean — $10
Redis: A 2GB, 2vCPUs instance with manually configured Redis running — $15
According to the performance, we might switch back to using Memorystore if the latency is affected by configuring a VPC with Cloud Run. Managed Postgres would be $30.
Scheduler + Pub: $2, it would be less than that, for sure.
Cloud Storage: With the Cache egress of 10 GiB in North America, it’d be < $5. But do correct me if I’m wrong here.
Back-end Server

We receive approximately 2,200,000 requests per month, let’s see how much it would cost us with our current Cloud Run configuration.
Database
We haven’t migrated the DB yet, since we’re still performing tests on the server and we wanna make sure that works well before migrating the Database, but these are the options we are considering
Digital Ocean Managed Postgres Instance
4GB, 2vCPU Managed Postgres with 1 standby node would only cost us $100 and if we’re doubling the performance to an 8GB, 4vCPU instance, it would be $120.
Total
Hypothetically, this configuration would only cost us around $200 compared to $734! That’s a 72% decrease in server costs! Nice.
Suppose in September, we had twice the traffic so it’d only cost us an additional $30 with Cloud Run. Or if he had to double the Database performance or increase the performance of our cache, it’d cost us only an additional $100 with one standby node or an additional $20 with no standby node. It still won’t cost us half of the bill on AWS.
Ending Notes
I’m very confident in the setup we have on Cloud Run but still, it pays to be cautious so we’re only rolling this new server out first to beta testers to see how it holds and to measure if the system we have in place is working right. Then after we know for sure it’s reliable, we’ll roll out the server to maybe 10% of the users while iterating and optimizing for performance.
The server is already configured with CI/CD but once we’re sure even the CRON architecture is logging and generating metrics right, we’ll set up CI/CD there too.
As for the database, we’re taking it slow with migrating that. Migrating everything together is quite reckless and since the database is the most crucial part of this whole architecture, we’ll prove the reliability of the other systems first and then move onto working on migrating the database with proper precautions in place.
Eventually, I’d like to unify the infrastructure using Terraform. The company is small enough to manage these set up on their own that we do not need to bring in additional complexity, training costs, and expertise to run something like Terraform but a fun exercise nonetheless.
If you feel how I designed this could be improved, I’d love to hear your feedback! If you want to hire me as a consultant hit me up at guyandtheworld@gmail.com.
Additional Reading
why-i-think-gcp-is-better-than-aws-ea78f9975bda
using-memorystore-with-cloud-run-82e3d61df016